

Поможет ли AutoML исследователю данных или заменит его?
Автор: Дмитрий Ходыкин, руководитель AI/ML проектов в компании ITentika
ЧАСТЬ 1
Назначение AutoML-решений
Решения класса AutoML позволяют пользователям с небольшим опытом автоматизировать процесс построения и развертывания моделей машинного обучения, не прибегая к услугам исследователей данных и инженеров в области машинного обучения. Автоматизации подлежат рутинные задачи, такие как предварительная обработка данных, выбор признаков (features), выбор модели и настройка гиперпараметров.
К практическим преимуществам AutoML отнесем следующие:
-
Минимизация рутины. Решения AutoML автоматизируют повторяющиеся и трудоемкие задачи, позволяя пользователям сосредоточиться на более важных с точки зрения бизнеса задачах, таких как анализ данных и интерпретация моделей. Общеизвестна статистика, что в проектах машинного обучения около 60-70% затрат времени приходится на подготовку данных. Мечта любого исследователя – освободиться от этой рутины.
-
Поиск максимальной точности. Решения AutoML могут выполнять полный перебор архитектур моделей и их гиперпараметров, что может привести к созданию моделей с максимально возможной точностью по сравнению с моделями, построенными человеком. Людям свойственно лениться, это заложено в их программах защиты психического здоровья. Не каждый исследователь готов тратить время и силы на полный перебор и оптимизацию параметров модели. Зачастую дело ограничивается поиском и перебором нескольких наиболее часто используемых моделей и параметров. Например, количеством решающих деревьев, глубиной дерева и т. п.
-
Снижение порога входа в исследование данных. Решения AutoML облегчают неспециалистам построение и развертывание моделей машинного обучения, что может привести к более широкому внедрению машинного обучения в различных отраслях и организациях.
Процесс создания и разворачивания модели машинного обучения будем называть конвейером (pipeline), который обычно включает несколько ключевых этапов:
-
Подготовка данных (data wrangling) – первый и часто самый трудоемкий шаг в разработке ML-решения. Сюда входят такие задачи, как очистка и предварительная обработка данных, обработка недостающих значений (data imputation) и разделение данных на обучающие, проверочные и тестовые наборы.
-
Выбор признаков (feature selection). После подготовки данных следующим шагом является выбор наиболее значимых признаков для модели. Для этого необходимо определить признаки, обладающие наибольшей предсказательной силой, и удалить все избыточные признаки, так как зачастую они только ухудшают результативность модели.
-
Выбор модели (model selection). Когда признаки отобраны, необходимо выбрать подходящую модель. Решения AutoML обычно используют комбинацию таких методов, как байесовская оптимизация и генетические алгоритмы, чтобы выбрать модель, которая лучше всего работает на данном наборе данных.
-
Тонкая настройка гиперпараметров (fine-tuning). Эти параметры контролируют поведение модели, например скорость обучения или количество скрытых слоев в нейронной сети. Решения AutoML обычно используют такие методы, как поиск по сетке или байесовская оптимизация для нахождения оптимальных гиперпараметров.
-
После тонкой настройки модели нужно оценить ее эффективность. Обычно оценка включает в себя измерение различных метрик качества модели, таких как accuracy, precision, recall и других показателей качества модели на тестовом (заранее отложенном) наборе данных.
-
Разворачивание модели (deployment). После того, как модель оценена и результат оценки удовлетворяет бизнес, наступает время разворачивания модели для промышленной эксплуатации. Для этого необходимо сделать модель доступной на сервере или облачной платформе для конечных пользователей через API или веб-интерфейс.
Таким образом, пройдя все этапы подготовки данных, обучения и разворачивания модели, пользователь получает инструмент для создания прогнозов на новых данных, генерируемых системой управления бизнеса.
Глобальный и российский рынок AutoML
Глобальный рынок автоматизированного машинного обучения оценивается в 631,0 млн долларов США в 2022 году, и ожидается, что в течение 2022-2030 годов он будет расти с темпом 49,2%, достигнув 16 млрд долларов США к 2030 году. Ключевые факторы, ответственные за рост отрасли, включают растущий спрос на эффективные решения для обнаружения мошенничества и растущую потребность в персонализированных рекомендациях продуктов (https://www.psmarketresearch.com/market-analysis/automated-machine-learning-market).
В России рынок AutoML также растет, но несколько медленнее по сравнению с мировым рынком. По прогнозам, к 2025 году объем российского рынка AutoML достигнет 1 млрд долларов США, а темпы роста составят 25%. Несмотря на замедление темпов роста, рынок в России по-прежнему представляет собой значительную возможность для компаний, предлагающих решения для автоматизации машинного обучения.
Российское правительство также инвестирует в развитие искусственного интеллекта, хотя объем инвестиций в рамках целевых программ был существенно пересмотрен в 2023 году (https://www.kommersant.ru/doc/5773647). Однако ожидается, что внедрение автоматизации в различных отраслях экономики, таких как энергетика, транспорт, ритейл, агропром, будет в том числе стимулировать рынок AutoML. Основными проблемами рынка, которые не дают ему раскрыться в полной мере, остаются нехватка квалифицированных специалистов и ограниченный доступ к финансированию для стартапов.
Лидеры глобального рынка
Gartner – это исследовательская и консультационная компания, которая регулярно публикует отчеты и оценки различных игроков на различных технологических рынках, включая AutoML. Согласно Магическому квадранту Gartner для платформ AutoML, лидерами рынка по состоянию на 2021 год являются следующие игроки (состав игроков 2021/2019 принципиально не изменился).
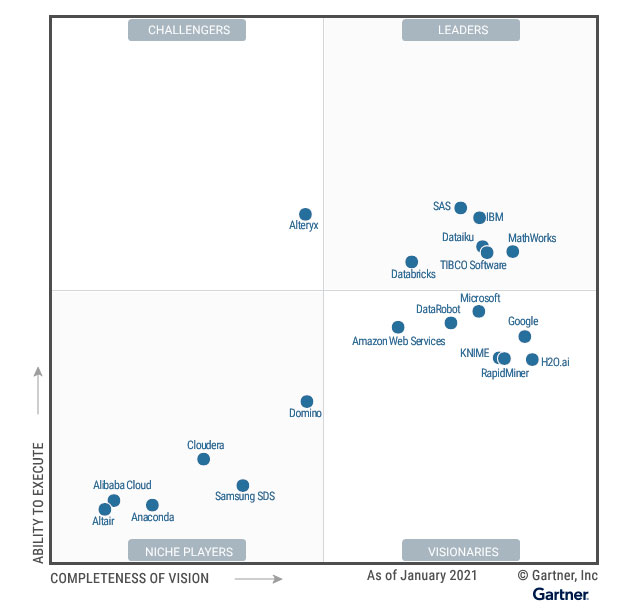
Dataiku. Платформа позиционируется разработчиками как единое решение для повседневных разработок в области искусственного интеллекта. Есть приложение для десктопа с web-интерфейсом (бесплатно для персонального использования), которое также может быть доступно на сервере для команды из нескольких пользователей (доступно по платной лицензии). В целом, решение удобное и эффективное при наличии определенного навыка работы с ETL-инструментами. Каждый шаг обработки данных и построения модели конфигурируется визуально при помощи так называемых рецептов (иконок с настраиваемыми параметрами). Выход одного рецепта служит входом для другого. Похожий подход моделирования использует и KNIME. Порог входа в решения – средний.
MathWorks. Компания MathWorks предоставляет решение под названием MATLAB, которое содержит свой язык программирования высокого уровня и среду для численных вычислений. MATLAB поддерживает широкий набор алгоритмов машинного обучения, включая глубокое обучение, деревья решений и алгоритмы кластеризации. Складывается впечатление, что MATLAB попал на квадрат Gartner AutoML по ошибке, так как выбивается из ряда других решений. По сути MathWorks – это надежный и проверенный помощник математика для разработки модели. Уровень автоматизации решения низкий.
Databricks – облачная платформа. Databricks интегрируется с широким спектром популярных источников данных, таких как Amazon S3, Google Cloud Storage и Azure Data Lake. С точки зрения автоматизации, Databricks предоставляет ряд возможностей, таких как автоматическая создания и отбора признаков, выбор лучшей модели и настройка гиперпараметров. Порог входа в решение – средний.
Недалеко отстали от лидеров «большие» облачные AutoML-платформы, такие как AWS Sagemaker и Google VertexAI. Эти платформы имеют определенные особенности:
-
Довольно высокий порог входа как с точки зрения компетенций (интерфейс действительно сложно назвать интуитивно понятным для непрофессионала), так и с финансовой точки зрения. Пара часов обучения модели могут обойтись в 100 долларов США, что намекает на коммерческое использование продукта среди крупных компаний. Да и с доступностью оплаты этих средств теперь существуют большие проблемы.
-
Платформы являются B2B-решениями для разработчиков крупных data-платформ и состоят из большого количества различных решений для ETL, хранения данных, запуска заданий по расписанию, фреймворков и библиотек машинного обучения, таких как TensorFlow, PyTorch и Apache MXNet и т.п. Без опыта работы с каждым отдельным инструментом построение единой готовой платформы нереализуемо.
-
Возможность обрабатывать большие объемы данных и масштабироваться по мере необходимости. Это также позволяет разработчикам создавать большие платформы под нужны крупного бизнеса. Для малого бизнеса стоимость разработки будет недоступной.
-
В России наметилась устойчивая тенденция перехода с указанных платформ на отечественные решения в силу проблем с оплатой сервисов, а также туманной перспективой доступа к сервисам в будущем.
Отечественные альтернативы
Вероятно, единственной полноценной альтернативой таких решений, как Dataiku и KNIME, на российском рынке является Loginom. По аналогии с импортными решениями, существуют версии для локального использования на компьютере разработчика, а также серверные версии для средних и крупных компаний. Подходы к моделированию в Loginom также схожи с подходами Dataiku и KNIME. Отдельно стоит отметить, что недостающий базовый функционал решения может быть расширен Python-модулем, позволяющим создавать кастомные модели машинного обучения для специфичных запросов бизнеса.
Среди альтернатив облачных AutoML можно выделить следующие решения:
-
Yandex DataSphere. Разработчики решения заявляют, что они первыми в мире (в 2020 году) запустили продукт для машинного обучения на технологии бессерверных вычислений, что позволяет подключать вычислительные мощности в тот момент, когда они требуются. Вероятно, поэтому тарификация за использование сервиса – посекундная (впрочем, как и у следующей платформы).
-
Sber ML Space. Внутри решения есть различные вычислительные кластеры, загрузка которых не однородна: есть новые кластеры, которые развиваются, есть более ранние и максимально загруженные. Автоматизация построена на фреймворке LightAutoML, который также развивает подразделение «Сбера».
Оба решения поддерживают хранение большого объема данных на различных классах хранилищ по скорости обмена данными и стоимости хранения. Загрузка и хранение данных организованы через бакеты (аналогично AWS и совместимо с S3). Оба решения поддерживают интерфейс JupyterLab для работы с данными и моделями. Порог входа в решения – средний +.
Изучив имеющиеся на рынке решения для AutoML, мы пришли к выводу, что слабо представлены продукты с «околонулевым» порогом входа, которые могли бы использовать не профильные специалисты в исследовании данных. Другими словами, упомянутые ранее решения – это не замена исследователя данных, а инструмент для него. Во второй части материала рассмотрим наш опыт в создании решения с минимальным порогом входа.


