

Уравнение с неизвестными: оценка трудоемкости проектов машинного обучения
Не каждую задачу следует решать с применением машинного обучения (ML). Попытки нарушить это правило встречаются по причине крайней популярности ML в последние годы и повышения доступности вычислительных ресурсов. Машинное обучение имеет смысл применять тогда, когда задача не имеет явного алгоритмического решения, т.е. вы не можете явно задать условия решения и описать в явном виде тот результат, которого собираетесь достигнуть при соблюдении заданных условий. Решение алгоритмических задач с применением ML возможно, но оно зачастую будет требовать больших вычислительных ресурсов, чем «лобовой» подход.
В настоящей статье мы рассмотрим параметры и подходы оценки стоимости ML-проектов, вынеся за скобки оценку разработки ПО и решение различных оптимизационных задач.
Что важно знать про особенности проектов машинного обучения
- Высокая доля неопределенности. В отличие от проектов разработки ПО, где часто можно точно определить требования и завершить разработку программы, проекты ML обычно требуют нескольких итераций в сборе требований, уточнения метрик качества моделей и других вводных проекта. Зачастую заказчик проекта не может по объективным причинам точно описать образ результата, либо в ходе проекта выявляются важные детали, которые трансформируют, уточняют этот образ.
-
Зависимость от качества данных. Результаты проекта ML в значительной степени зависят от качества данных, используемых для обучения модели. Не в каждом наборе данных получится найти зависимости, полезные для осознания и развития бизнеса, для автоматизации рутинных действий, поэтому перед стартом проекта важно проанализировать имеющиеся данные. Кроме того, необходимо учитывать возможные ошибки, отклонения и пропуски в данных при оценке трудоемкости проекта.
-
Важность прототипирования. Среди этапов ML-проектов важно выделять построение прототипа решения, после которого решение о его дальнейшем продолжении и трудоемкости принять значительно легче с опорой на жизнеспособные данные и алгоритмы. Стоит отметить, что заказчики часто стараются игнорировать данный этап и не принимают его ценность для своего бизнеса.
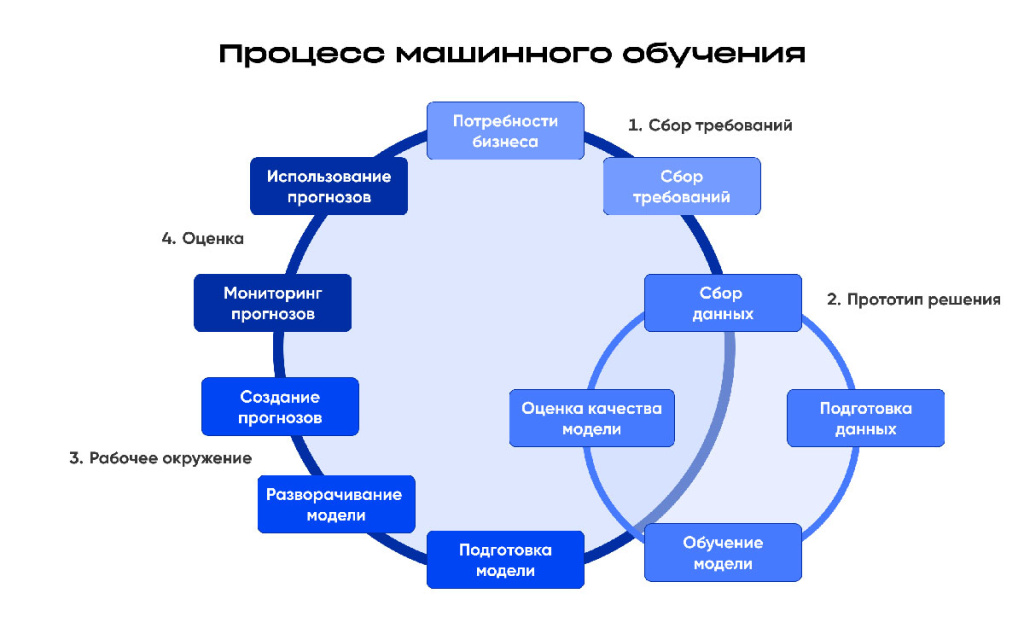
- Необходимость работы с большими объемами данных и высокая требовательность к вычислительным ресурсам. В проектах ML обычно используются большие объемы данных для обучения моделей и оценки их качества. Это может повлиять на время/вычислительные ресурсы, необходимые для загрузки, обработки и анализа данных.
- Необходимость экспертного мнения. В проектах ML часто требуется экспертное (доменное) мнение для осознания специфики данных, смыслового наполнения признаков данных, а также для оценки качества модели и выбора оптимальных алгоритмов и параметров. Это может повлиять на время, необходимое для срабатывания команды, и на квалификацию персонала, участвующего в проекте.
Обобщим вышесказанное и сделаем вывод, что до начала проекта машинного обучения сложно предугадать его результат, при этом требуются значительные ресурсы вычислительных мощностей и дефицитные специалисты, что, к тому же, удорожает проект при его без того высокой рискованности.
Параметры оценки трудоемкости проектов ML
При всей сложности и неопределенности оценки ML-проектов делать это требуется каждый раз, когда заказчик приходит со своей задачей.
Зачастую трудоемкость зависит от множества факторов, таких как:
- Размер данных и их представление. Объем данных, необходимый для обучения модели, значительно влияет на трудоемкость проекта. Чем больше данных требуется для обучения, тем больше времени и ресурсов понадобится на обучение модели.
- Качество данных неизбежно влияет на трудоемкость проекта. До 50% времени проекта, а иногда и больше, может уйти на подготовку обучающего набора. Подбор стратегии обогащения данных, различные подходы к заполнению недостающих значений – все это отражается на качестве итоговой модели, а, следовательно, требует значительного внимания со стороны ML-инженеров.
- Сложность задачи и модели. Задачи ML бывают разной сложности, требующих разных методов, подходов, а также их комбинации. Для того чтобы модели правильно усваивали сложные зависимости, скрытые в данных, сами модели усложняют, используют их ансамбли и комбинации. Очевидно, что на подбор архитектуры сложного решения, а также на настройку его параметров требуется больше времени, чем для решений простых.
-
Стек технологий. Некоторые инструменты могут упростить работу с данными и обучением модели. Например, решения класса AutoML ускоряют процесс подготовки данных, обучения модели и ее настройки. Мы любим использовать такие решения на старте проекта и при подготовке POC, чтобы сделать стоимость начальной стадии проекта для клиента более интересной и ускорить принятие решения о дальнейших инвестициях в проект.
Способы оценки трудоемкости проектов ML
Далее рассмотрим некоторые подходы к оценке трудоемкости проектов ML, которые мы применяем на практике.
- Декомпозиция проекта на отдельные задачи. В основе декомпозиции обычно лежит тот функционал, который требуется клиенту, и который он ожидает увидеть по итогу реализации проекта. Далее каждая задача оценивается на основе предыдущего опыта или экспертного мнения. Оценка выполняется на основе времени, необходимого для выполнения задачи. Складывая трудоемкость оценок, получаем оценку общую.
- Экспертная оценка. Тут мы привлекаем опытных коллег с профилем опыта, релевантным решаемой задаче. Это не только инженеры в области ML, но и доменные специалисты из таких областей, как ритейл, финансы, агропром и т.п. Опыт и мнение коллег из разных направлений хорошо накладывается друг на друга, «переопыляется».
Следующие методы более интересные. Я бы их назвал – «сапожник с сапогами», поскольку оценка трудоемкости ML-проекта осуществляется с применением ML.
- Статистический анализ. Метод предполагает анализ данных прошлых проектов по параметрам, перечисленным выше (и не только). Регрессионные модели, построенные на таких данных, получают на вход данные нового проекта и помогают принимать решения о его стоимости. У нас есть опыт обучения моделей для предсказания отдельных параметров оценки проекта, например, предсказание стоимости труда разработчиков в зависимости от их региона, квалификации, стека и др.
- Деревья решений. Метод предполагает создание дерева решений, где каждая ветвь представляет собой определенный фактор (объем данных, сложность модели, количество этапов и т.д.), влияющий на трудоемкость проекта. Каждый фактор имеет свой вес, который определяется на основе прошлого опыта и экспертного мнения из обучающих данных.
Таким образом, главной особенностью оценки ML-проекта является слабая прогнозируемость его результата. На начальных этапах этот результат уточняется, детализируются критерии его оценки, строится базовая модель, что снижает риски как заказчика, так и исполнителя. Однако стоит отметить, что российский бизнес не очень любит финансировать исследовательские стадии ML-проектов, что является чуть ли не главной причиной конфликтности между заказчиком и исполнителем. Вместе с тем, пройдя исследовательскую стадию проекта, заказчик уже может получить инсайты по точкам роста своего бизнеса, еще до построения сложных моделей.
В сложных проектах, оценка которых затруднена, помогают модели машинного обучения, обученные на данных предыдущих проектов. Это позволяет учесть скрытые зависимости между параметрами проекта и «застраховать» потери времени на неявных на первый взгляд задачах.
